一 HTTP协议
HTTP(HyperText Transfer Protocol,超文本传输协议)是一个属于应用层的面向对象的协议,由于其简捷、快速的方式,适用于分布式超媒体信息系统。它于1990年提出,经过几年的使用与发展,得到不断地完善和扩展。HTTP是一个基于TCP/IP通信协议来传递数据(HTML 文件, 图片文件, 查询结果等)。
HTTP协议的特点
- 支持客户端/服务器(B/S)模式
- 简单快速:客户向服务器请求服务时,只需传送请求方法和路径。请求方法常用的有GET、HEAD、POST。每种方法规定了客户与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快。
- 灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。
- 无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
- 无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
客户端通过HTTP想服务器请求资源的过程
- 浏览器分析连接指向的URL,
- 浏览器请求DNS服务器解析域名的IP地址。
- 根据IP地址浏览器与服务器建立TCP连接,
- 浏览器发出请求(GET)
- 服务器响应,发送资源。
- 释放TCP连接。
HTTP请求
客户端通过一个HTTP请求从服务器请求消息。HTTP请求分为请求行,请求头,空行,请求数据。
1.请求行:请求行由三个标记组成–请求方法,请求URI和HTTP版本,它们由空格分隔。
例如:
1 | GET /index.html HTTP/1.1 |
HTTP规范定义了八种可能的请求方法:
- GET:检索URI中标识资源的一个简单请求
- HEAD:与GET方法相同,服务器只返回状态行和头标,并不返回请求文档
- POST:服务器接受被写入客户端输出流中的数据的请求
- PUT:服务器保存请求数据作为指定URI新内容的请求
- DELETE:服务器删除URI中命名的资源的请求
- OPTIONS:关于服务器支持的请求方法信息的请求
- TRACE:Web服务器反馈Http请求和其头标的请求
- CONNECT:已文档化但当前未实现的一个方法,预留做隧道处理
2.请求头标:由关键字/值对组成,每行一对,关键字和值用冒号(:)分隔。
请求头标通知服务器有关于客户端的功能和标识(cookie就是放在请求头中),典型的请求头标有:
User-Agent 客户端厂家和版本
Accept 客户端可识别的内容类型列表
Content-Length 附加到请求的数据字节数
3.空行:最后一个请求头标之后是一个空行,发送回车符和退行,通知服务器以下不再有头标。
4.请求数据:使用POST传送数据,最常使用的是Content-Type和Content-Length头标。
HTTP响应
Web服务器解析请求,定位指定资源。服务器将资源副本写至套接字(即端口),在此处由客户端读取。
一个响应由四个部分组成;状态行、响应头标、空行、响应数据
1.状态行:状态行由三个标记组成:HTTP版本、响应代码和响应描述。
HTTP版本:向客户端指明其可理解的最高版本。
响应代码:3位的数字代码,指出请求的成功或失败,如果失败则指出原因。
响应描述:为响应代码的可读性解释。
例如:HTTP/1.1 200 OK
HTTP响应码:
- 1xx:信息,请求收到,继续处理
- 2xx:成功,行为被成功地接受、理解和采纳
- 3xx:重定向,为了完成请求,必须进一步执行的动作
- 4xx:客户端错误,请求包含语法错误或者请求无法实现
- 5xx:服务器错误,服务器不能实现一种明显无效的请求
下表显示每个响应码及其含义:
1 | 100 继续。客户端应继续其请求 |
2.响应头标:像请求头标一样,它们指出服务器的功能,标识出响应数据的细节。
3.空行:最后一个响应头标之后是一个空行,发送回车符和退行,表明服务器以下不再有头标。
4.响应数据:HTML文档和图像等,也就是HTML本身。
浏览器解析HTTp响应显示数据的过程:
- 浏览器首先解析状态行,查看表明请求是否成功的状态代码。
- 然后解析每一个响应头标,头标告知以下为若干字节的HTML。
- 读取响应数据HTML,根据HTML的语法和语义对其进行格式化,并在浏览器窗口中显示它。
- 一个HTML文档可能包含其它需要被载入的资源引用,浏览器识别这些引用,对其它的资源再进行额外的请求,此过程循环多次。
HTTP1.0与HTTP1.1的区别
一个WEB站点每天可能要接收到上百万的用户请求,为了提高系统的效率,HTTP 1.0规定浏览器与服务器只保持短暂的连接,浏览器的每次请求都需要与服务器建立一个TCP连接,服务器完成请求处理后立即断开TCP连接,服务器不跟踪每个客户也不记录过去的请求。但是,这也造成了一些性能上的缺陷,例如,一个包含有许多图像的网页文件中并没有包含真正的图像数据内容,而只是指明了这些图像的URL地址,当WEB浏览器访问这个网页文件时,浏览器首先要发出针对该网页文件的请求,当浏览器解析WEB服务器返回的该网页文档中的HTML内容时,发现其中的图像标签后,浏览器将根据
标签中的src属性所指定的URL地址再次向服务器发出下载图像数据的请求,如下图所示。
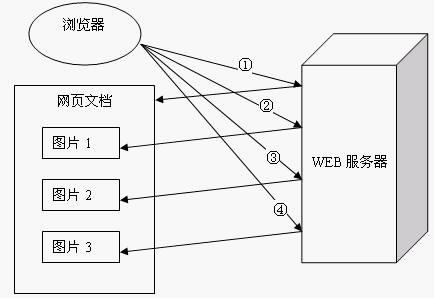
显 然,访问一个包含有许多图像的网页文件的整个过程包含了多次请求和响应,每次请求和响应都需要建立一个单独的连接,每次连接只是传输一个文档和图像,上一次和下一次请求完全分离。即使图像文件都很小,但是客户端和服务器端每次建立和关闭连接却是一个相对比较费时的过程,并且会严重影响客户机和服务器的性 能。当一个网页文件中包含Applet,JavaScript文件,CSS文件等内容时,也会出现类似上述的情况。
为了克服HTTP 1.0的这个缺陷,HTTP 1.1支持持久连接,在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟。一个包含有许多图像的网页文件的多个请求和应答可以在一个连接中传输,但每个单独的网页文件的请求和应答仍然需要使用各自的连接。HTTP 1.1还允许客户端不用等待上一次请求结果返回,就可以发出下一次请求,但服务器端必须按照接收到客户端请求的先后顺序依次回送响应结果,以保证客户端能够区分出每次请求的响应内容,这样也显著地减少了整个下载过程所需要的时间。基于HTTP 1.1协议的客户机与服务器的信息交换过程,如下图所示。
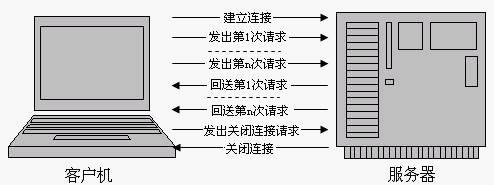
可见,HTTP 1.1在继承了HTTP 1.0优点的基础上,也克服了HTTP 1.0的性能问题。不仅如此,HTTP 1.1还通过增加更多的请求头和响应头来改进和扩充HTTP 1.0的功能。例如,由于HTTP 1.0不支持Host请求头字段,WEB浏览器无法使用主机头名来明确表示要访问服务器上的哪个WEB站点,这样就无法使用WEB服务器在同一个IP地址和端口号上配置多个虚拟WEB站点。在HTTP 1.1中增加Host请求头字段后,WEB浏览器可以使用主机头名来明确表示要访问服务器上的哪个WEB站点,这才实现了在一台WEB服务器上可以在同一个IP地址和端口号上使用不同的主机名来创建多个虚拟WEB站点。HTTP 1.1的持续连接(长连接),也需要增加新的请求头来帮助实现,例如,Connection请求头的值为Keep-Alive时,客户端通知服务器返回本次请求结果后保持连接;Connection请求头的值为close时,客户端通知服务器返回本次请求结果后关闭连接。HTTP 1.1还提供了与身份认证、状态管理和Cache缓存等机制相关的请求头和响应头。(具体的可以看HTTP的RFC规范)
HTTP1.1与HTTP2.0的区别
HTTP/2(超文本传输协议第2版,最初命名为HTTP 2.0),是HTTP协议的的第二个主要版本,使用于万维网。HTTP/2是HTTP协议自1999年HTTP 1.1发布后的首个更新,主要基于SPDY协议。
与HTTP/1相比,主要区别包括:
- HTTP/2采用二进制格式而非文本格式
- HTTP/2是完全多路复用的,而非有序并阻塞的——只需一个连接即可实现并行
- 使用报头压缩,HTTP/2降低了开销
- HTTP/2让服务器可以将响应主动“推送”到客户端缓存中
HTTP/2为什么是二进制?
比起像HTTP/1.x这样的文本协议,二进制协议解析起来更高效、“线上”更紧凑,更重要的是错误更少
为什么 HTTP/2 需要多路传输?
HTTP/1.x 有个问题叫线端阻塞(head-of-line blocking), 它是指一个连接(connection)一次只提交一个请求的效率比较高, 多了就会变慢。HTTP/1.1 试过用流水线(pipelining)来解决这个问题, 但是效果并不理想(数据量较大或者速度较慢的响应, 会阻碍排在他后面的请求). 此外, 由于网络媒介(intermediary )和服务器不能很好的支持流水线, 导致部署起来困难重重。而多路传输(Multiplexing)能很好的解决这些问题, 因为它能同时处理多个消息的请求和响应; 甚至可以在传输过程中将一个消息跟另外一个掺杂在一起。所以客户端只需要一个连接就能加载一个页面。
消息头为什么需要压缩?
假定一个页面有80个资源需要加载(这个数量对于今天的Web而言还是挺保守的), 而每一次请求都有1400字节的消息头(着同样也并不少见,因为Cookie和引用等东西的存在), 至少要7到8个来回去“在线”获得这些消息头。这还不包括响应时间——那只是从客户端那里获取到它们所花的时间而已。这全都由于TCP的慢启动机制,它会基于对已知有多少个包,来确定还要来回去获取哪些包 – 这很明显的限制了最初的几个来回可以发送的数据包的数量。相比之下,即使是头部轻微的压缩也可以是让那些请求只需一个来回就能搞定——有时候甚至一个包就可以了。这种开销是可以被节省下来的,特别是当你考虑移动客户端应用的时候,即使是良好条件下,一般也会看到几百毫秒的来回延迟。
服务器推送的好处是什么?
当浏览器请求一个网页时,服务器将会发回HTML,在服务器开始发送JavaScript、图片和CSS前,服务器需要等待浏览器解析HTML和发送所有内嵌资源的请求。服务器推送服务通过“推送”那些它认为客户端将会需要的内容到客户端的缓存中,以此来避免往返的延迟。
二 HTTPS简介
由于HTTP通信是明文通信的,这样发送中的数据将受到威胁。如:
- 窃听风险(eavesdropping):第三方可以获知通信内容。
- 篡改风险(tampering):第三方可以修改通信内容。
- 冒充风险(pretending):第三方可以冒充他人身份参与通信。
因此出现了HTTPS,希望达到:
- 所有信息都是加密传播,第三方无法窃听。
- 具有校验机制,一旦被篡改,通信双方会立刻发现。
- 配备身份证书,防止身份被冒充。
概述
HTTPS 可以认为是 HTTP + TLS/SSL,它的发展历史如下:
- 1994年,NetScape公司设计了SSL协议(Secure Sockets Layer)的1.0版,但是未发布。
- 1995年,NetScape公司发布SSL 2.0版,很快发现有严重漏洞。
- 1996年,SSL 3.0版问世,得到大规模应用。
- 1999年,互联网标准化组织ISOC接替NetScape公司,发布了SSL的升级版TLS 1.0版。
- 2006年和2008年,TLS进行了两次升级,分别为TLS 1.1版和TLS 1.2版。最新的变动是2011年TLS 1.2的修订版。
目前常用的 HTTP 协议是 HTTP1.1,常用的 TLS 协议版本有如下几个:TLS1.2, TLS1.1, TLS1.0 和 SSL3.0。其中 SSL3.0 由于 POODLE 攻击已经被证明不安全,但统计发现依然有不到 1% 的浏览器使用 SSL3.0。TLS1.0 也存在部分安全漏洞,比如 RC4 和 BEAST 攻击。TLS1.2 和 TLS1.1 暂时没有已知的安全漏洞,比较安全,同时有大量扩展提升速度和性能,推荐大家使用。需要关注一点的就是 TLS1.3 将会是 TLS 协议一个非常重大的改革。不管是安全性还是用户访问速度都会有质的提升。不过目前没有明确的发布时间。同时 HTTP2 也已经正式定稿,这个由 SPDY 协议演化而来的协议相比 HTTP1.1 又是一个非常重大的变动,能够明显提升应用层数据的传输效率。
HTTPS原理
HTTPS内容加密的过程可以简述成:用对称加密来加密数据,用公钥加密来加密对称加密的秘钥(这句话其实并不准确,因为通信是传输的并不是秘钥本身,而是用于生成秘钥的随机数)。要实现这个客户端和服务器要通过四次握手。如下图:

1.客户端发出请求(ClientHello)
首先,客户端(通常是浏览器)先向服务器发出加密通信的请求,这被叫做ClientHello请求。在这一步,客户端主要向服务器提供以下信息:
- 支持的协议版本,比如TLS 1.0版。
- 一个客户端生成的随机数,稍后用于生成”对话密钥”。(这是关键)
- 支持的加密方法,比如RSA公钥加密。
- 支持的压缩方法。
2.服务器回应(SeverHello)
服务器收到客户端请求后,向客户端发出回应,这叫做SeverHello。服务器的回应包含以下内容:
- 确认使用的加密通信协议版本,比如TLS 1.0版本。如果浏览器与服务器支持的版本不一致,服务器关闭加密通信。
- 一个服务器生成的随机数,稍后用于生成”对话密钥”。
- 确认使用的加密方法,比如RSA公钥加密。
- 服务器证书。(含公钥加密的公钥,用于加密premaster_secrect)
除了上面这些信息,如果服务器需要确认客户端的身份,就会再包含一项请求,要求客户端提供”客户端证书”。比如,金融机构往往只允许认证客户连入自己的网络,就会向正式客户提供USB密钥,里面就包含了一张客户端证书。
3.客户端回应
客户端收到服务器回应以后,首先验证服务器证书。如果证书不是可信机构颁布、或者证书中的域名与实际域名不一致、或者证书已经过期,就会向访问者显示一个警告,由其选择是否还要继续通信。如果证书没有问题,客户端就会从证书中取出服务器的公钥。然后,向服务器发送下面三项信息:
- 一个随机数。该随机数用服务器公钥加密,防止被窃听。(这个随机数就是premaster_secrect)
- 编码改变通知,表示随后的信息都将用双方商定的加密方法和密钥发送。
- 客户端握手结束通知,表示客户端的握手阶段已经结束。这一项同时也是前面发送的所有内容的hash值,用来供服务器校验。
此时客户端和服务器同时都有了三个随机数,它们将通多相同的秘钥生成器(秘钥生成算法)来获得相同的“会话秘钥”。
至于为什么使用三个随机数而不是直接随机生成秘钥,大神们回答如下:
“不管是客户端还是服务器,都需要随机数,这样生成的密钥才不会每次都一样。由于SSL协议中证书是静态的,因此十分有必要引入一种随机因素来保证协商出来的密钥的随机性。对于RSA密钥交换算法来说,pre-master-key本身就是一个随机数,再加上hello消息中的随机,三个随机数通过一个密钥导出器最终导出一个对称密钥。pre master的存在在于SSL协议不信任每个主机都能产生完全随机的随机数,如果随机数不随机,那么pre master secret就有可能被猜出来,那么仅适用pre master secret作为密钥就不合适了,因此必须引入新的随机因素,那么客户端和服务器加上pre_master secret三个随机数一同生成的密钥就不容易被猜出了,一个伪随机可能完全不随机,可是是三个伪随机就十分接近随机了,每增加一个自由度,随机性增加的可不是一。”
此外,如果前一步,服务器要求客户端证书,客户端会在这一步发送证书及相关信息。
4.服务器的最后回应
- 编码改变通知,表示随后的信息都将用双方商定的加密方法和密钥发送。
- 服务器握手结束通知,表示服务器的握手阶段已经结束。这一项同时也是前面发送的所有内容的hash值,用来供客户端校验。
至此,整个握手阶段全部结束。接下来,客户端与服务器进入加密通信,就完全是使用普通的HTTP协议,只不过用”会话密钥”加密内容。